生産現場におけるヒヤリハットの要因を質問形式で点検し安全性を向上、質問文を作成するだけで点検項目の変更に対応可能、安全モニタリングの省力化に貢献。放送コンテンツや監視カメラ映像からのシーン検索などへの応用も可能
概要
当社は、汎用性が高く、画像に対する質問に世界最高精度で回答できる質問応答AIを開発しました。本AIは、画像に映る人物や物だけでなく背景を含めて色、形状、状態などの情報を用いて質問し、回答が得られることが特徴です。これにより、従来は困難だった人物や物の場所や状況を反映した質問応答が可能となります。例えば、生産現場における潜在的な危険(ヒヤリハット)要因の検知に適用でき、「人物が黒いマットの上にいるか」など、現場ごとのルールにあわせて作業員が所定の場所(黒い絶縁マットなど)に立っているかどうかを確認することができます。汎用性の高い質問応答AIの実現により、画像と質問を用意するだけで使用目的に合わせた作り込みを行う必要がなくなります。
当社は公開データセット(*1)を用いた実験において、画像とテキストの膨大なデータで事前に調整していない場合(以下、事前学習なし)は66.25%、事前に調整した場合(以下、事前学習あり)は74.57%と、それぞれ世界最高精度のAI回答正解率を達成しました。本AIを生産現場の安全モニタリングに適用することで、現場の安全性向上と監督者の作業省力化の両立が期待できます。また、放送コンテンツや監視カメラ映像からの特定シーン検索などへの応用も可能です。
当社は、本技術の詳細を、ニューラルネットワークに関する国際会議ICANN2021(*2)で9月14日に発表しました。
開発の背景
近年、労働災害による死亡者数は減少する一方で、休業4日以上の死傷者数は増加傾向にあります(*3)。今後、人手不足の常態化が想定される中、生産現場の安全性の確保は喫緊の課題です。特にコロナ禍においては、労働者の安全確保と管理監督の省力化の両立が求められています。最近では、現場支援を目的としたAIの導入が進んでおり、AIビジネスの国内市場は2025年には2020年度比約2倍の1兆9,357億円になると予測されています(*4)。例えば、現場のカメラ映像から「帽子を装着しているか」「作業場の通路に物が落ちていないか」などを確認する安全点検をAIでサポートすることにより、現場の安全確保に加え管理者の作業を省力化することができます。
従来の画像認識AIは、人、帽子、作業着など事前に学習した個々の物体を検出することはできますが、点検項目に合わせて何をもとに点検箇所の判定をするのか(判定機能)を作り込む必要がありました。例えば、「帽子を装着しているか」という点検項目では、人物の頭部に帽子が検出されたかどうかで判定します。状況が変化する生産現場においては、点検項目の変更や追加にも即座に対応することが重要ですが、従来のAIでは変更後の点検項目に合わせて判定機能を作り込む時間がかかるため、すぐに対応することは困難でした。
本技術の特徴
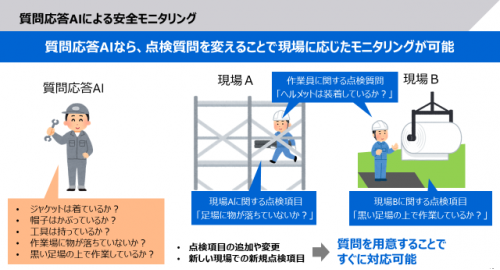
そこで当社は、画像に対する質問に世界最高精度で回答し、質問の変更や追加に容易に対応できる質問応答AIを開発しました。本AIは、画像に映る人物や物だけでなく背景を合わせて認識し、画像の特徴と質問文の特徴を横断的に処理して回答を導き出します。人物や物の有無だけでなく、それらの場所や状況など様々な情報を含んだ膨大な画像・質問・回答のセットを学習可能で、約3,000種類の回答の選択肢から、質問に応じて適切な回答を提示することができます。「画像+質問」という汎用的なフォーマットのため、点検項目の変更や追加の際にも、項目に合わせて質問文を用意するだけで柔軟に対応できます(図1)。
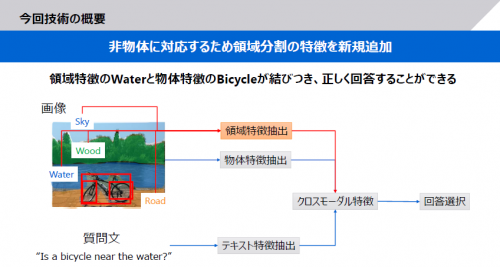
画像に対する質問応答AI(*5)は世界中で研究が進む最新技術で、画像および質問文から抽出した特徴を融合して回答を導き出します。従来手法(*6)は、主に画像内に映る人物や物の特徴を考慮して回答しますが、当社が今回開発した方式は、これらの人物や物が存在する床や通路などの背景や空間領域の特徴も抽出し、背景を合わせて認識することで、より画像内の物の状況を反映した回答が可能になります(図2)。例えば、「物があるか」ということだけでなく「通路に物が置いてあるか」「人物が所定の位置に立っているか」などの安全モニタリングで重要となる質問に対応できます(図3、4)。本AIを、生産現場の安全モニタリングに適用することで、現場の安全性向上と監督者の作業省力化の両立、また働き方改革への貢献が期待できます。
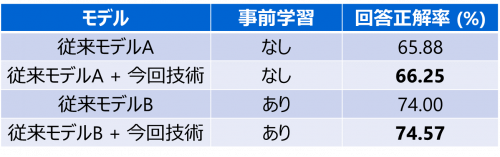
当社が実施した世界的標準の公開データセットを用いた性能評価において、従来手法の回答正解率は、事前学習なしの場合65.88%、事前学習ありの場合74.00%であるのに対し、本AIの回答正解率は、事前学習なしの場合66.25%、事前学習ありの場合74.57%と、画像に対する質問回答の世界最高精度(*7)を達成しました(図5)。
図1:質問応答AIによる安全モニタリング
図2:開発したAIの特徴
図3:画像に対する質問応答結果の例(左画像は(*8)、右画像は(*9)より引用)
図4:画像に対する質問応答結果の例
図5:従来手法との精度比較
今後の展望
本AIは画像と質問から回答を推定する用途に汎用的に適用できるため、放送コンテンツからの特定シーンの検索、ドライブレコーダーや監視カメラ映像からの特定の状況や人物の検索、状況が類似した過去のヒヤリハット事例検索など、絞り込み条件に質問文を用いた画像検索への応用も期待できます。
当社は、点検項目の仕様変更を柔軟に行える安全モニタリングシステムへの2023年度中の導入を目指し、システム開発および回答精度の更なる向上を進めてまいります。
*1 VQA-v2データセット
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.:VQA: Visual Question Answering. In: ICCV (2015)
*2 ICANN2021:The 30th International Conference on Artificial Neural Networks。9月14日から17日までオンラインで開催される。
*3 厚生労働省労働基準局 安全衛生部安全課が示す令和2年 労働災害発生状況
https://www.mhlw.go.jp/content/11302000/000775170.pdf
*4 AIビジネスの国内市場
オートメーション新聞 https://www.automation-news.jp/2021/07/57280/
*5 画像を含めた質問応答システム(VQA:Visual Question Answering)
*6 Li, Linjie and Gan, Zhe and Cheng, Yu and Liu, Jingjing :Relation-aware Graph Attention Network for Visual Question Answering :ICCV(2019)
*7 事前学習あり/なしの各モデルに対し、論文投稿時点で世界最高精度を確認
*8 厚生労働省 岡山労働局 サイト
https://jsite.mhlw.go.jp/okayama-roudoukyoku/news_topics/kantokusho_oshirase/niimipato.html
*9 厚生労働省 働き方改革 特設サイト
https://hatarakikatakaikaku.mhlw.go.jp/file60/