2024-12-17
株式会社 東芝
学習データが十分にない産業分野においても、少数の実画像による「事前学習」で、
迅速かつ高精度に解析する「画像解析AI」を開発
~顕微鏡画像や赤外線画像、生体画像など収集できる画像が少なく、
従来AI導入が難しかった専門分野の自動化・省人化に貢献~
概要
当社は、「画像解析AI」において、事前学習に必要な学習データが十分に得られない顕微鏡画像や赤外線画像、生体画像といった特殊な装置や環境下で撮影した産業用途の画像(非自然画像)でも、少数の実画像データから学習データを自動生成し、迅速かつ高精度に解析できる画像解析AIを開発しました。本AIは、独自の事前学習方式を特長とし、従来画像解析AIの活用が難しかった産業分野での適用が可能になり、解析の自動化による効率化・省人化に貢献します。
当社は、インターネット上で公開されている赤外線画像・顕微鏡画像・ウェハ画像・病理画像・眼底画像の5種類の非自然画像データセット(*1)からそれぞれランダムに40~1,000枚の少量の実画像データを選択し、本AIの効果を検証しました。学習データ画像の枚数を、数十倍から数百倍になるまで自動生成して事前学習した本AIで画像を解析したところ、130万枚の実画像の学習データを持つ代表的な大規模自然画像データセットを用いて事前学習した場合を上回る精度で対象画像を識別することに成功しました。一般的に高精度な画像解析の実現には数万枚以上の大量の実画像データが必要ですが、本AIは最小40枚という少数の実画像データで迅速に高精度な解析を実現します。
当社は本技術の詳細を、12月8日から12日にベトナムで開催された国際会議ACCV2024 (17th Asian Conference on Computer Vision) にて発表しました。
開発の背景
人口減少に伴う人手不足解消や人手で行ってきた作業の効率化のために、産業現場における画像解析AIの適用が進んでいます。例えば、半導体製品の不良種別を評価する品質検査において、画像解析AIによって推定した不良種別と各製造工程の処理履歴を対応付けることで、不良原因を特定し生産性向上に繋げることができます。
一般的に高精度な画像解析AIを構築するには、数万枚以上の大量の実画像データでAIを学習させる必要がありますが、実利用の場面においては 、特殊な環境下または専用の装置で撮影する画像は撮影に時間やコストを要するため、入手できる画像が小規模となる傾向にあります。半導体製品の開発工程で用いられるウェハ画像などでは大量の画像データを収集するのは困難です。また、生体画像のような倫理やプライバシーの観点から二次利用ができないデータも同様です。さらに、新規検査の立ち上げや開発工程における一時的な検査においては、画像データが小規模の段階で解析して詳細の解析が必要かどうかを判断し、短期間で開発にフィードバックしたいといったニーズがあります。
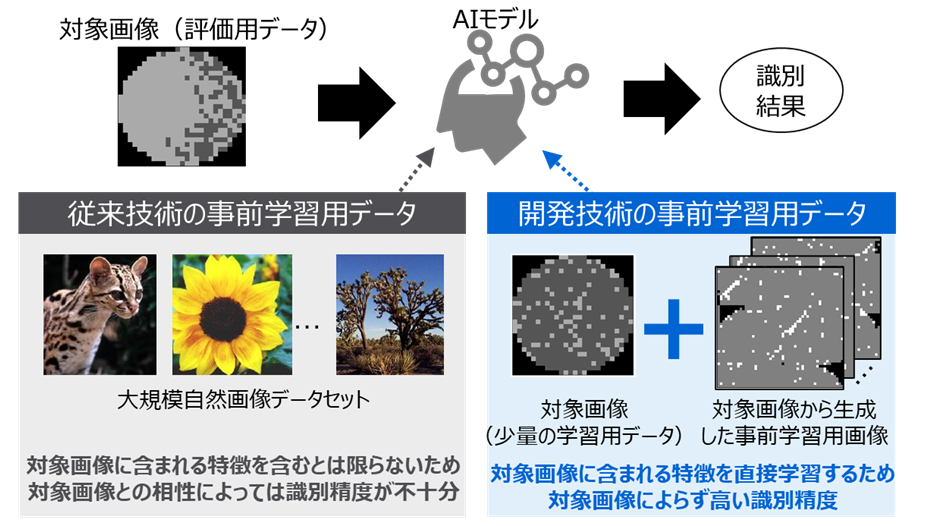
AI開発においては、少量の画像データしか用意できない場合には、解析したい画像と特性の近い画像からなる大規模なデータセットを用いて、画像の特徴をAIに事前に学習させることで解析精度を向上させる「事前学習」が有効です。「事前学習」においては、動植物や乗り物といった被写体を一般的なカメラで撮影した画像(自然画像)からなる大規模自然画像データセットを用いて「事前学習」する方法が一般的ですが、製造現場や医療現場などで専用の装置で撮影された産業画像(非自然画像)は自然画像とは画像の特徴が異なるため十分な精度が得られないという課題がありました(図1)。
図1:自然画像と非自然画像の例
本技術の特徴
そこで当社は、事前学習に必要な学習データが十分に得られない産業用途の画像でも、独自の「事前学習」技術を用いて、少数の実画像データから学習データを自動生成し、迅速かつ高精度に解析できる画像解析AIを開発しました。考案した「事前学習」技術は、一般的なカメラで撮影した自然画像ではなく、専用の装置で撮影された産業用途の非自然画像(対象画像)を事前学習用のデータとして用います。対象画像の一部を切り出した画像を複数組み合わせ、その各画像をランダムに回転・反転させ1枚の画像として結合したものから、再度部分的に画像を切り出すことで、似たような特徴を持つ画像を生成します(図2、図3)。こうして生成した画像を学習データとして事前学習させることで、自然画像を用いる場合とは異なり、解析対象の画像と類似の画像を用いた学習を実現し、画像解析AIの精度が向上します。一般的に、AIの学習には、学習データの収集とデータ作成に時間とコストがかかるという課題がありますが、本技術は少量の画像データのみで迅速に高精度な画像解析を実現します。開発技術によって事前学習用の大量のデータは自動生成され、その事前学習は数時間程度(*2)で処理可能なため、さまざまな産業の現場で解析の自動化による効率化・省人化に貢献するとともに、製品開発における解析の必要性の有無を判断し短期間で開発にフィードバックしたいといったニーズにも対応します。
図2:従来技術と開発技術の比較
図3:本技術における事前学習用画像の生成手順
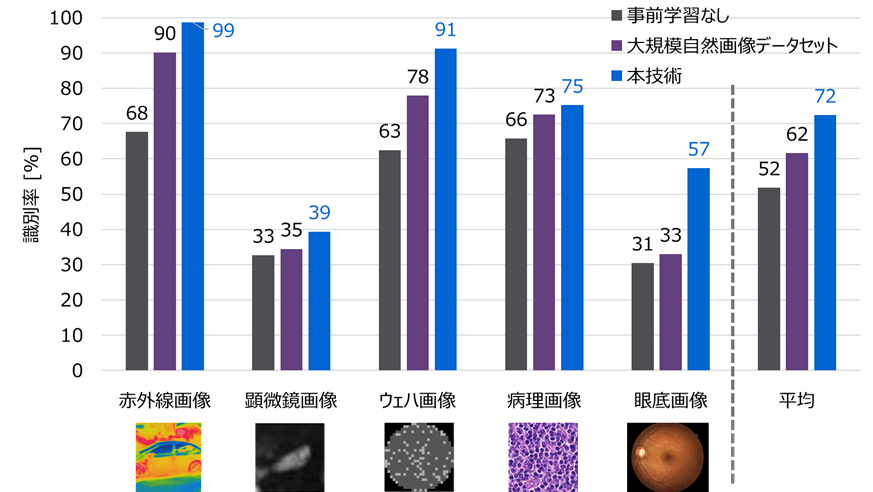
当社は本AIの精度について、公開されている5種類の非自然画像データセット(赤外線画像、顕微鏡画像、ウェハ画像、病理画像、眼底画像)で評価しました。それぞれのデータセットにおいて、ランダムに選択した40~1,000枚の少量の画像データを用いて9,000~30,000枚の事前学習用画像を生成し、画像識別タスク評価を行いました。評価の結果、本技術を用いて事前学習することで、代表的な大規模自然画像データセットの1つであるImageNet(学習データは130万枚)を用いて事前学習した場合を上回る精度で画像を識別することに成功しました(図4)。
図4:非自然画像公開データセットを用いた識別タスクでの評価結果
今後の展望
本AIを用いることで、学習データとなる実画像が少なく、AIの導入を諦めていたさまざまな現場で画像解析AIを活用できるようになります。少数の画像で自動検査ラインを立ち上げたい工場や、少数の生体画像で病気の有無を判別したい医師・医用機器メーカー、少数の顕微鏡画像で自動識別機能を実現したい医薬品・化粧品メーカーなど、さまざまな産業分野の発展に寄与できるものです。
当社は今後、東芝デジタルソリューションズ(株)と連携し実証を進めるとともに、さらなる精度向上を進め、早期の実用化を目指します。
*1 本文中の画像の出典は以下の通り。
自然画像: Li, F.-F., Andreeto, M., Ranzato, M., & Perona, P. Caltech 101 (1.0) [Data set]. CaltechDATA. https://doi.org/10.22002/D1.20086. (2022)
赤外線画像:Ashfaq, Q., Akram, U., Zafar, R.: Thermal image dataset for object classification.
https://data.mendeley.com/datasets/btmrycjpbj (2021)
顕微鏡画像:Yang, J., Shi, R.,Wei, D., Liu, Z., Zhao, L., Ke, B., Pfister, H., Ni, B.: Medmnist v2-
a large-scale lightweight benchmark for 2d and 3d biomedical image classification.
Scientific Data 10(1), 41 (2023)
ウェハ画像:Wu, M.J., Jang, J.S.R., Chen, J.L.: Wafer map failure pattern recognition and
similarity ranking for large-scale data sets. IEEE Transactions on Semiconductor
Manufacturing 28(1), 1–12 (2015)
病理画像:Veeling, B.S., Linmans, J., Winkens, J., Cohen, T., Welling, M.: Rotation equivariant
cnns for digital pathology. In: Medical Image Computing and Computer
Assisted Intervention – MICCAI 2018. pp. 210–218. Springer International Publishing
(2018)
眼底画像:Wang, Z., Yang, J.: Diabetic retinopathy detection via deep convolutional networks
for discriminative localization and visual explanation. In: AAAI Workshop. pp.
514–521 (2018)
*2 学習用画像のサイズ、学習用画像の枚数、学習に使うマシンスペックに寄る。顕微鏡画像の場合、28x28ピクセル、160枚の画像を対象に、高性能GPU(NVIDIA A100 Tensor Core GPU)を搭載したマシンを使うと事前学習にかかる時間は6時間程度。なお、社名および商品名はそれぞれ各社が商標または登録商標として使用している場合があります。