近年、人間の言語(自然言語)をコンピュータで処理し内容を抽出する自然言語処理の分野において、汎用的な大規模言語モデルの開発が世界中で活発に行われています。言語モデルとは、自然言語による質問応答や文章生成などができるAIで、米OpenAIが開発した「GPT-3」が代表的ですが、2022年5月には、米Metaが「GPT-3」に匹敵する大規模言語モデル「Open Pretrained Transformer(OPT-175B)」を研究者向けに公開するなど、英語圏を中心に開発競争を繰り広げています。こうしたなか、日本語に特化した大規模言語モデルの開発も盛んになってきており、今後の動向が注目されています。
言語モデルの大規模化が性能向上に直結
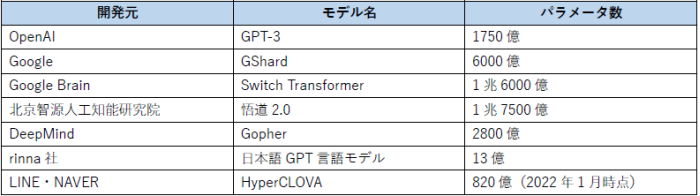
2020年5月の「GPT-3」リリース以降、言語モデルの大規模化は加速しています。言語モデルの性能を表す一つの指標であるパラメータ数は「GPT-3」で1750億個に上り、前バージョン「GPT-2」の約117倍以上となりました。また2021年6月には、中国政府による資金援助を受けている北京智源人工知能研究院が1兆7500億ものパラメータを持つ「悟道2.0」を発表するなど、言語モデルの大規模化は引き続き効果的だと判断されています。日本語に特化した大規模言語モデルは、LINE社がNAVER社と共同開発を進めている「HyperCLOVA」や、rinna社が開発した「日本語GPT言語モデル」などがありますが、現時点では、先述した英語圏などの言語モデルに比べると規模が小さいと言えます。
表1:代表的な言語モデルとパラメータ数
日本語に特化した大規模言語モデルの開発が加速
英語圏の言語モデルで日本語を使用する際、コーパス(言語資源データ)が少なく、さらにノイズが多いため、上手く除去しなければならないという課題があり、またインターネット上のテキストは、ウィキペディアのコピーが多いことから適切な教師データも少ないという状況でした。さらに日本語は、語順の自由度が高いことや日常における必須語が多いこと、様々な表記や同じ音で異なる言葉が存在すること、方言の多様性から同じ意味の単語でも異なる単語の組み合わせになること、また、話し言葉では文中の主語や目的語を省略したりしがちなので、テキストを読む際に文中の単語の省略を考慮しながら意味を解釈していく必要があることなど、独自の難しさがあります。それゆえに、これらの課題を解消しようと日本語に特化した言語モデルの進化が期待されているのです。
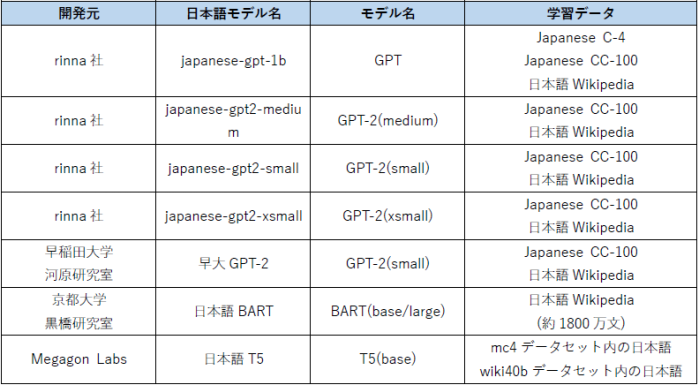
こうしたなか、LINE社とNAVER社が日本語に特化した言語モデルを「GPT-3」レベルで開発すると力を注いでいるのが「HyperCLOVA」です。「HyperCLOVA」は、膨大なデータを学習させたモデルにより、少量の言語をインプットすることで文脈にあった言語処理を可能とし、人間との自然でスムーズな対話を実現しています。現在、パラメータ数が67億・130億・390億の3つのモデルがあり、390億モデルでは、会話の滑らかさ、そしてトピックの追従度は98パーセントの性能を誇っています。また、2022年1月時点で820億モデルの開発が進んでおり、さらに2022年中には、2040億以上のモデルが活用されていくということです。これらのモデル構築に使われているコーパス「LINE LM Corpus」は、2019年以降「BERT(言語モデル)」のモデル構築のために作られたコーパスをベースにしており、現在、約100億サンプル・約1.8テラバイト・約5000億トークンに達し、徐々にサイズと品質が向上しているそうです。現在、「HyperCLOVA」以外にも、日本語に特化した大規模言語モデルの開発は活発に行われており、フリーで使用できるモデルの公開からコミュニティ形成が広がりつつあります。
表2:フリーで利用可能な日本語に特化した大規模言語モデル
新聞記事本文から高精度な「見出し」を自動生成
自然言語処理を活用したAIサービスのビジネス適用が様々な業界で進むなか、NTTデータ先端技術は河北新報社と、新聞記事の「本文」を読み込ませることで自動的に「見出し」を生成させる実証実験を行っています。これには、「GPT-3」と同様のテキスト生成を得意とする言語モデル「日本語版MASS」が活用されており、過去の新聞記事6万件を学習していることから、生成された見出しは日本語として自然で、人間が書いたものと見分けがつかないぐらい高精度です。