日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:島田 明、以下「NTT」)は、大規模言語モデル(LLM)によって文書を視覚情報も含めて理解する視覚読解技術を実現しました。実験において、文書画像を提示しながら、あらゆる質問への回答を行う人工知能(AI)の実現への可能性を示唆する結果が得られており、デジタルトランスフォーメーション(DX)におけるコア技術として期待されます。
なお、本成果はNTT版大規模言語モデル「tsuzumi※1」のアダプタ技術として採用・導入されております。本成果は、LLMベースの視覚文書読解に関する具体的な方法論を示した世界初の論文として、2024年2月20日~2月27日にカナダ・バンクーバーで開催されたAI分野における最高峰の国際会議であるThe 38th Annual AAAI Conference on Artificial Intelligence※2 (AAAI2024、採択率23.8%) において発表されました。また、2024年3月11日~3月15日に日本・神戸で開催された国内最大規模の自然言語処理に関する研究を扱う会議である自然言語処理学会第30回年次大会※3(NLP2024)にて、優秀賞(投稿論文中 上位2%)を受賞しました。
1.背景
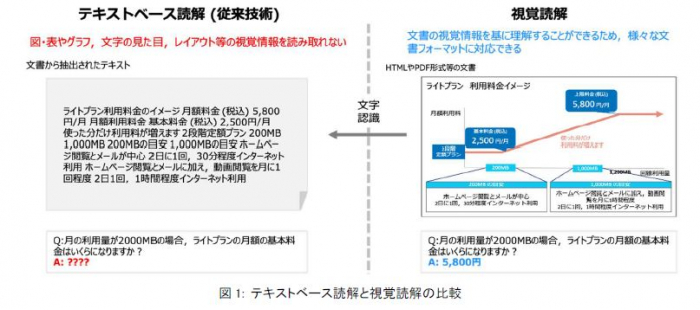
我々が扱う文書はテキストや視覚要素(アイコンや図表など)を含み、多様な種類・形式が存在します。こうした実世界の文書を読解し理解する技術の実現は、AI分野における重要課題の一つです。一方で、LLMを始めとする現在のAIは、人間の読解能力を超えるなど大きく発展してきましたが、文書中のテキスト情報しか理解できない限界がありました。この問題に対して、NTTではヒトの情報理解と同様に、文書を視覚情報から理解する技術として、図1で示す「視覚読解技術※4」を提唱し、本技術の実現をめざして研究開発を進めております。
2. 研究の課題
これまでの視覚読解技術は任意のタスク(例えば、請求書に関する情報抽出タスク)に対して対応することができませんでした。目的のタスクごとに一定数のサンプルを用意して学習を行わない限り、所望のタスクで高い性能を出すことは難しい状況でした。そこで本研究は、汎用な言語理解・生成能力を持つLLMをベースとして、任意のタスク用の学習を行わなくても応答できる、高い指示遂行能力を視覚読解モデルで実現することを目指しました。具体的には、テキスト情報しか理解することができないLLMに対して、どのように文書画像に含まれる図表などの視覚情報をテキストと融合させてLLMに理解させるか、が本研究で解決を目指した課題となります。
3.研究の成果
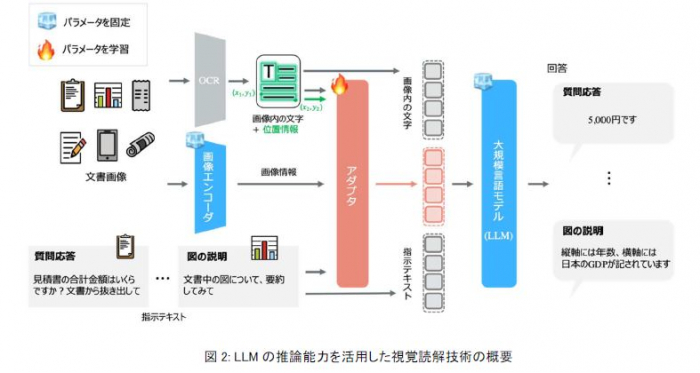
LLMの高い推論能力を活用し、視覚的に文書を理解する新たな視覚読解技術を世界に先駆けて開発しました(図2)。この実現に向けて本研究では、① 文書画像をLLMの表現に変換可能な新たなアダプタ技術※5の開発および、② 多様な視覚読解タスクを対象とした指示遂行データセットの構築を行いました。これにより、LLMが文書の内容を視覚と言語を融合して理解し、任意のタスクを追加学習なしで遂行することが可能となります。例えば、文書を検索・スクリーニングを行う業務、専門文献の読書補助などオフィス作業や日常生活におけるヒトの認知が必要なシーンにおいて、LLMを活用することが可能です。
4.研究のポイント
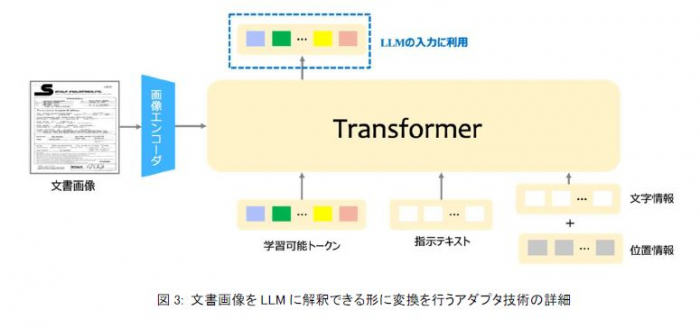
① 画像中の文字および位置(座標)、画像の特徴を定量的に表現した画像情報、指示テキストを同一空間上にマッピングし、LLMに繋ぐ新たなアダプタ技術を開発しました。図2で示すように、学習時には、モデルパラメータの大部分を占めるLLMや画像エンコーダのパラメータを固定にし、アダプタのみを学習対象にすることで、パラメータ効率の良い学習を実現しています。図3に示すように、本技術のアダプタでは、Transformer※6構造を採用し、学習可能なトークンに対して、相互注意※7では画像特徴との関係性を捉え、自己注意※7では指示テキストや画像中の文字および位置情報との関係性を捉えます。これにより、文書画像のマルチモーダルな特徴をLLMにとって解釈しやすい情報として獲得することができます。
② 文書画像を知識源とし、質問応答、情報抽出、文書分類を始めとする12種類の視覚読解タスクを、ヒトの指示を基に遂行する世界最大規模の指示遂行データセットを構築しました。
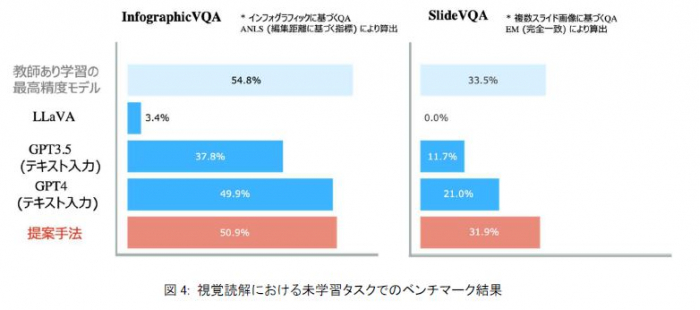
これらの貢献により、図4で示す様に、未学習のタスク※8、※9においても、目的タスクで学習を行なった教師あり学習モデルの性能やGPT-4(テキスト入力のみ)、画像を理解できるLLMであるLLaVA※10などに匹敵または凌駕する高い性能を達成しました。
5.研究協力の状況
本成果は、2023年度における東北大学 データ駆動科学・AI教育研究センター 鈴木潤 教授との共同研究の成果となります。
6.今後の展開
本技術は、視覚表現された文書を基に質問応答を行う技術やWeb検索など産業上重要なサービスの発展に貢献します。作業自動化をはじめ、ヒトと協働し、価値を生み出すAIの実現に向けて技術確立をめざします。
<用語解説>
※1 tsuzumi
NTT版大規模言語モデル。日本語の処理性能を重視し、独自の大量のテキストデータを使って学習された言語モデル。詳細は、報道発表をご参照ください。
URL:
https://www.rd.ntt/research/LLM_tsuzumi.html
※2 AAAI (Annual AAAI Conference on Artificial Intelligence)
人工知能に関するトップレベルの国際会議
URL:
https://aaai.org/aaai-conference/
※3 言語処理学会年次大会
日本国内において自然言語処理を扱う最大規模の学会
URL:
https://www.anlp.jp/nlp2024/
※4 視覚読解技術
文書を画像として捉え、視覚情報から理解し読解を行う技術。
※5 アダプタ技術
画像エンコーダとLLMの橋渡しとなるモジュール。
※6 Transformer
入力シーケンスを出力シーケンスに変換または変更するニューラルネットワークアーキテクチャの一種。
※7 相互注意と自己注意
二つの入力系列が与えられた時に、どこの入力箇所に注意すべきかを計算する機構。与えられる二つの系列が同一の場合、自己注意。そうでない場合は、相互注意と呼ばれる。
※8 InfographicVQA
インフォグラフィック(情報、データ、知識を視覚的に表現した文書)に対する質問応答タスク
URL:
https://rrc.cvc.uab.es/?ch=17&com=evaluation&task=3
※9 SlideVQA
複数スライド画像に対する質問応答タスク
URL:
https://github.com/nttmdlab-nlp/SlideVQA
※10 LLaVA
視覚と言語を統合した大規模モデル
URL:
https://llava-vl.github.io/