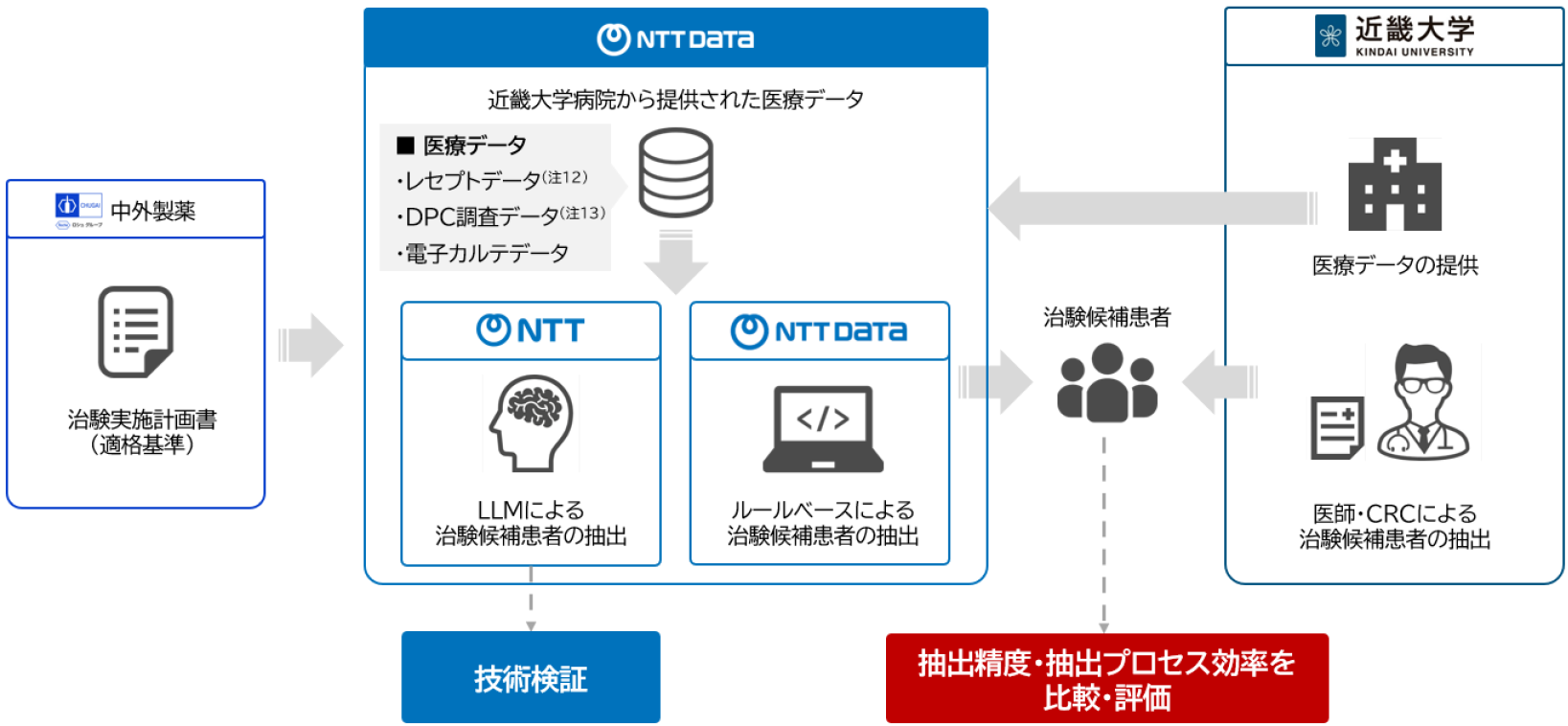
【本研究の意義】
本研究は、LLM活用による治験候補患者抽出の精度向上と抽出プロセスの効率化が、治験参加者組み入れまでのリードタイム短縮につながるかを定量的に検証するものです。これにより、治験全体の期間短縮、製薬企業の開発スピード向上、医療機関における治験実施体制のスリム化を図るとともに、患者が新たな治療選択肢へより迅速にアクセスできる環境の整備に貢献します。なお、AIの出力結果は医師の判断支援を目的としたものであり、最終的な診療判断は医師が行うことを前提とします。
【各機関の役割】
・近畿大学病院:医療データの提供、治験候補患者の抽出および抽出精度・抽出プロセス効率の
比較・評価
・中外製薬:治験実施計画書(適格基準)の提供および評価協力
・NTT:LLMによる治験候補患者抽出に関する技術検証(注14)の実施
・NTTデータ:ルールベースによる治験候補患者抽出の実施および、抽出精度・抽出プロセス効率の
比較・評価
なお、本研究は、2026年5月に近畿大学病院、NTTデータが発表した技術検証(注15)の成果で得られた知見を基盤としています。具体的には、治験参加者組み入れが進行中の治験実施計画書に定められた適格基準の下でリアルワールドデータを用い、治験候補患者抽出の有効性および実運用への適用可能性を評価するものです。
本研究の成果を踏まえ、関係各社は医療機関および製薬企業とのさらなる連携を通じたリアルワールドデータとAIを活用した治験候補患者抽出基盤の社会実装の可能性について検討を進めていきます。
【注釈】
注1 リアルワールドデータ:実際の診療現場において蓄積される医療データで、臨床試験や新薬開発、
医療の質向上などへの活用が進んでいる。
注2 大規模言語モデル(LLM):大量のテキストデータを学習し、文章の理解や生成を可能とする人工
知能技術。自然言語処理の分野で幅広く活用されている。
注3 治験実施計画書:新しい医薬品の効果や安全性を調べるために、治験の目的や方法、参加条件など
をあらかじめ定めた計画書。
注4 適格基準:治験の安全性や科学的な信頼性を確保するために、参加できる方の条件を年齢や症状な
どにより定めたもの。
注5 治験コーディネーター(CRC):医師や治験参加者、製薬企業などの関係者間を調整し、治験が適
切に実施されるよう支援する医療専門職。
注6 上市:新薬が薬事承認を受けた後に販売され、医療機関で使用できるようになること。
注7 千年カルテ:「医療分野の研究開発に資するための匿名加工医療情報及び仮名加工医療情報に関す
る法律」(次世代医療基盤法)に基づき、一般社団法人ライフデータイニシアティブと株式会社N
TTデータが国から認定を受けて、実施している事業の名称。
注8 ルールベース手法:治験実施計画書に定められた条件をあらかじめプログラム化し、治験候補患者
を抽出する手法。
注9 tsuzumi 2:NTT株式会社が開発した大規模言語モデル。日本語を含む多様な言語処理に対応して
いる。
注10 Python:データ解析やシステム開発などに広く利用されているプログラミング言語。
注11 SQL(Structured Query Language):データベースを操作するための言語。条件に基づくデータ
抽出や集計に使用される。
注12 レセプトデータ:医療機関が診療報酬を請求するために作成するデータで、診療内容や処方され
た薬剤などの情報が含まれる。
注13 DPC調査データ:入院医療において診断名や治療内容を整理したデータで、患者の病状や治療の
概要を把握するための情報が含まれる。
注14 LLMによる治験候補患者抽出に関する技術検証:NTT コンピュータ&データサイエンス研究所が
開発した技術を用いて検証を行う。
注15 2026年5月に近畿大学病院、NTTデータが発表した技術検証:リアルワールドデータを活用した
治験候補患者抽出の技術検証を実施し、その有効性を検証した取り組み。
(参照:
https://www.nttdata.com/global/ja/news/topics/2026/052500/ )
*「千年カルテ」は日本国内における一般社団法人ライフデータイニシアティブの登録商標です。
*「tsuzumi」はNTT株式会社の登録商標です。
*その他の商品名、会社名、団体名は、各社の商標または登録商標です。