発表のポイント:
- 高音質と低遅延を両立した深層学習に基づくリアルタイム音声変換技術を開発しました
- 新規に考案した話者依存性の低い音声特徴量の抽出処理で高音質を担保できたため、従来法とは異なり未来の音声信号のバッファが不要なモデルを用いた低遅延処理も実現できました
- 本技術は対面や遠隔を問わず、様々な音声コミュニケーションでの音声変換を可能にし、例えば、web会議にて発話者の抑揚や声質を聞き取りやすい音声に変換するなど、誰もが物理的・能力的・心理的な制約にとらわれないコミュニケーションの実現に寄与します
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:島田 明、以下「NTT」)は、ある話者の声を、まるで他の話者が話しているかのように、高品質かつ低遅延に音声変換する技術を考案しました(図1)。これにより、Web会議やライブ配信などでのリアルタイム音声変換が可能になります。今後はスマートフォンやVRデバイス上での利用など、さまざまな場面での応用が期待されます。
本成果は、6月24日より開催される、コミュニケーション科学基礎研究所オープンハウス2024に出展いたします。
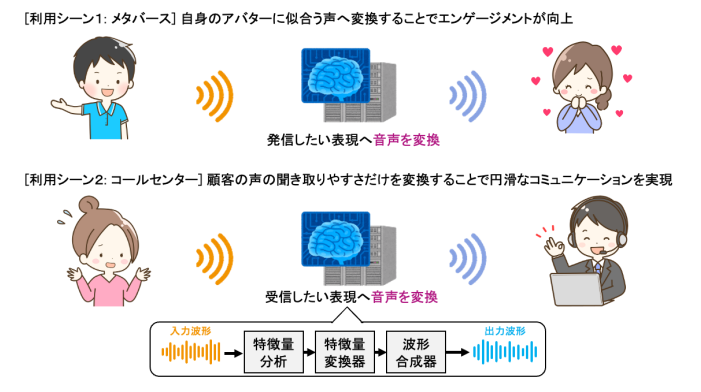
図1. 音声変換によるコミュニケーション拡張
1.背景
音声は、言語情報だけでなく話す人の抑揚や声質といった話者性など、非言語情報も伝達できるという大きな特徴を有し、利便性に特に優れたコミュニケーション媒体です。「もっと理想的な声で話したい・聞きたい」といったニーズはあるものの、手軽に実現できる技術はこれまで限られていました。音声変換は、言語内容を保持しつつ、声の特徴(声質、抑揚、リズムなど)を変更することで、ネイティブに近い英語の流暢な発音や、説得力のあるスピーチ、緊張による声の震えの解消など、物理的・能力的・心理的な制約にとらわれないコミュニケーションの実現に寄与します。その適用先は、プライバシー保護、エンターテインメント、医療、教育、ビジネスなど、多岐にわたります(図1)。
これらの利用シーンに応じて、「声のどの特徴を変換するべきか?」「その変換のためにはどういった学習データを用意すべきか?」「変換はリアルタイムである必要があるか?」など、様々な前提条件が想定されます。NTTではこれまでに、元話者と変換先話者の同一発話音声のペアデータを用いて、声質だけでなく抑揚やリズムなど柔軟に変換できる特徴量変換技術や、収集が高コストな元話者と変換先話者の発話ペア音声を必要としないペアデータフリーな学習方式を用いた特徴量変換技術の研究にも取り組んできました。
今回、これら音声の「特徴量変換技術」の研究成果と、独自に進めてきた音声特徴から音声波形を生成する「波形合成技術」の研究成果を融合し、Web会議を含むさまざまな音声コミュニケーションで使用可能である低遅延なリアルタイム音声変換技術を開発しました。
2.技術のポイント
(1) 高い変換性能
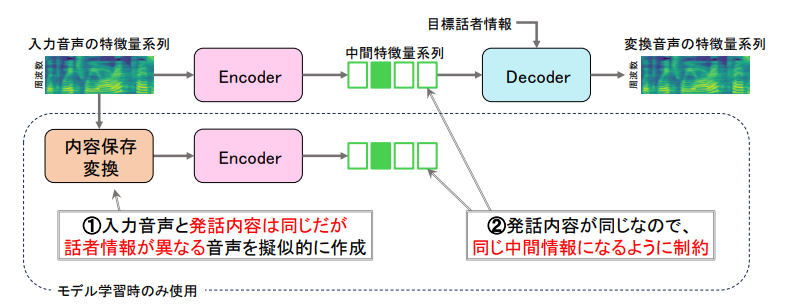
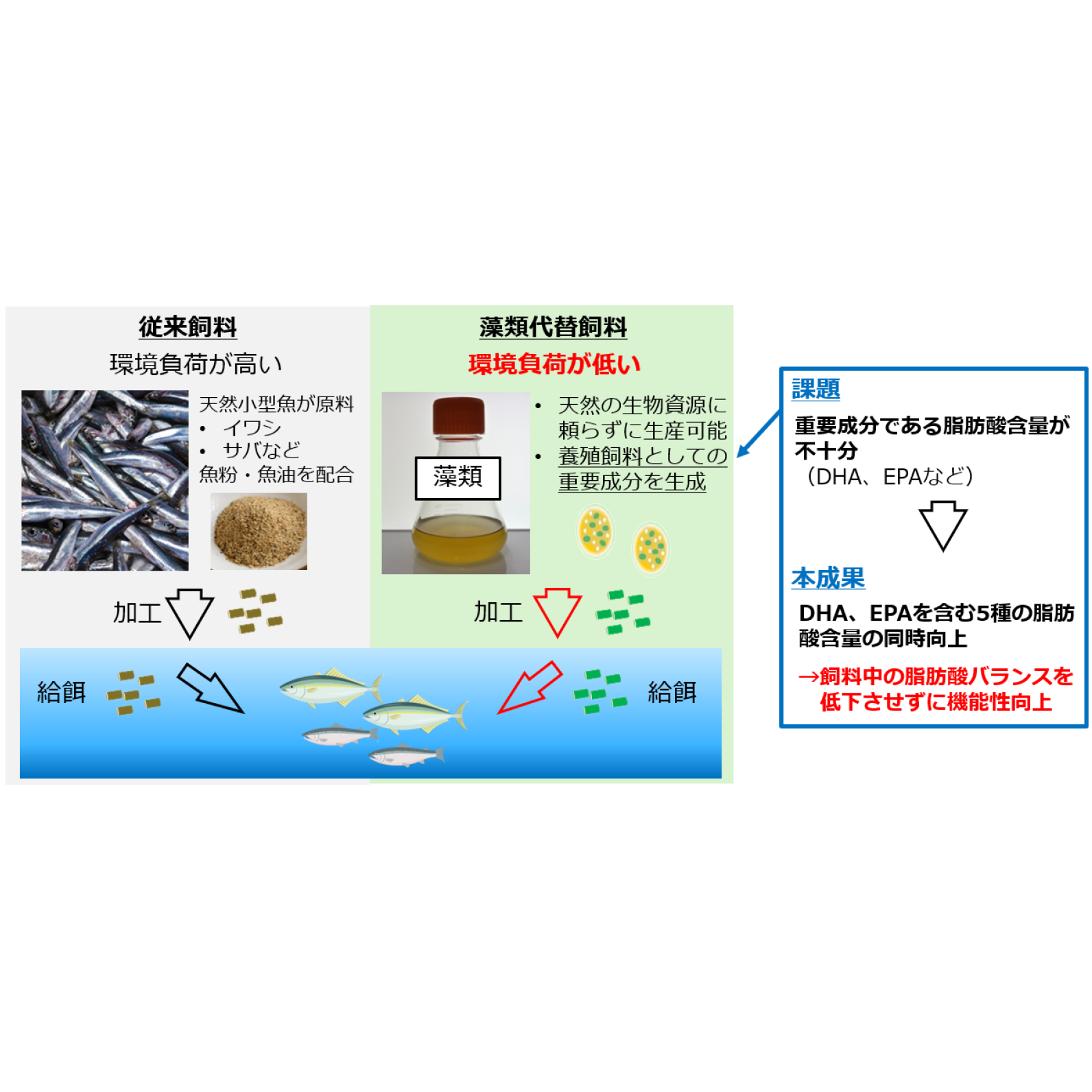
特徴量変換器では、ある話者の音声特徴量を別の話者の音声特徴量へ変換します。変換モデルは2つのモジュール(EncoderとDecoder)で構成されており、Encoderは入力音声から中間特徴量を抽出し、Decoderは抽出された中間特徴量に目標話者の情報を付与することで変換音声の特徴量を生成します。ここで、Encoderの出力である中間特徴量が十分に汎化された特徴量であることが重要です。例えば、異なる2話者が同じ文章を発声した際には、同じ中間特徴量が抽出されるべきです。
今回、従来の音声変換では、上述の場合に、同じ中間特徴量になっていないことを発見しました。中間特徴量に入力話者の話者情報が多く残留しており、変換性能の劣化が生じていたのです。そこで、入力音声と発話内容は同じですが話者情報が異なる音声(例えば、声の高さのみ低く加工した音声)を擬似的に生成し、入力音声の中間特徴量と、擬似的に作成された音声の中間特徴量とを近づける制約を新たに導入しました(図2)。これにより、従来法に比べて中間特徴量における話者情報の残留が1万分の1以下に低減されます。この話者依存性の低い音声表現の獲得により、結果として高品質な特徴量変換を実現しました。本技術で変換された音声特徴をNTTで独自に進めてきた軽量・高速動作可能な波形合成器に入力することで、最終的な変換音声の波形を得ることができます。
図2. 特徴量の変換方法
(2) 低遅延な変換処理
会話する際に、人は自分の話し声を聞きながら喋っています。これをフィードバック音声と言いますが、「遅延聴覚フィードバック」研究では、フィードバック音声をわざと大きく遅らせると非常に発話しづらくなることが知られています。そのため、音声変換システムを通った変換音声を発話者が聞く状況下では、スムーズな発話のため、音声変換で生じる遅延を数十ミリ秒に抑えることが必要となってきます。
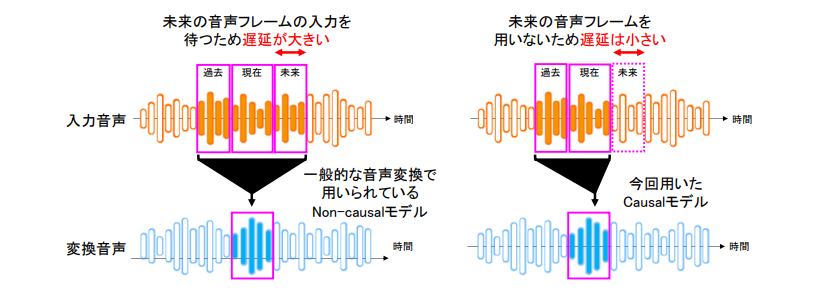
一般的な音声変換では、変換精度を高めるため、多くの情報を入力として与えます。例えば、ある時刻の変換音声を生成する際に、当該時刻の入力音声フレームだけでなく未来の入力音声フレームも同時に用いる(non-causal)モデルを用いて変換を行います(図3)。一方で、未来フレームの入力を待つため、大きな遅延が生じてしまいます。
今回のリアルタイム音声変換では、低遅延な動作を保証するため、未来フレームを一切使わず、当該時刻と過去の音声フレームのみから変換音声を生成する(causal)モデルを採用する必要があります。一方で、causalモデルを単純に適用すると、未来フレーム分の情報が入力から減ってしまうため、変換精度の劣化が生じます。今回、上で紹介したポイント(1)に示す技術と組み合わせることで高品質と低遅延を両立したリアルタイム音声変換を実現しました。
図3. 低遅延なモデル
3.実験の概要
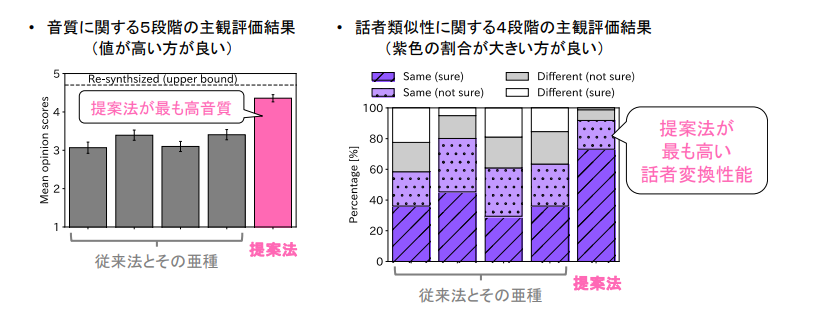
従来法・今回の手法を用いて変換した音声の品質を、音質に関しては5段階(1: 非常に悪い、2: 悪い、3: 普通、4: 良い、5: 非常に良い)、目標話者との話者類似性に関しては、4段階(1: 違う、2: 多分違う、3: 多分同じ、4: 同じ)の評価尺度で聴取実験を行いました。特徴量変換器では、従来法に比べ、音質・話者類似性ともに従来法を大きく凌ぐ結果となり、発話者の違いにより生じる差異を明示的に小さくする今回の手法が有効であることがわかりました(図4)。
図4. 実験の結果
5.今後の展開
本技術により、発声機能障がいへの活用(例えば、無喉頭音声の聞き取りやすさの改善)、ネイティブに近い流暢な英語の発音、説得力のあるスピーチ、緊張による声の震えの解消など、対面・遠隔を問わずビジネスや実生活の多様なシーンにおいて音声コミュニケーションを豊かにすることが期待されます。
今後は、実環境使用を想定した対雑音性向上や安定性向上などに取り組むと共に、なりすましへの対策などにも取り組み、より安心して好みの音声でコミュニケーションできる未来をめざします。
【用語解説】
※1.深層学習:機械学習の1種でディープラーニングとも呼ばれることもある、近年注目されている学習手法
※2.話者依存性:元話者の声や発音の特徴がどれだけ影響を与えるかを示す性質
※3.無喉頭音声:喉頭を使わずに発声された音声、例えば電気式人工喉頭を用いて発声された音声など